
GMP模型
特别提醒,本文所涉及的源码是
go1.22.4 darwin/amd64文件位置:runtime/map.go
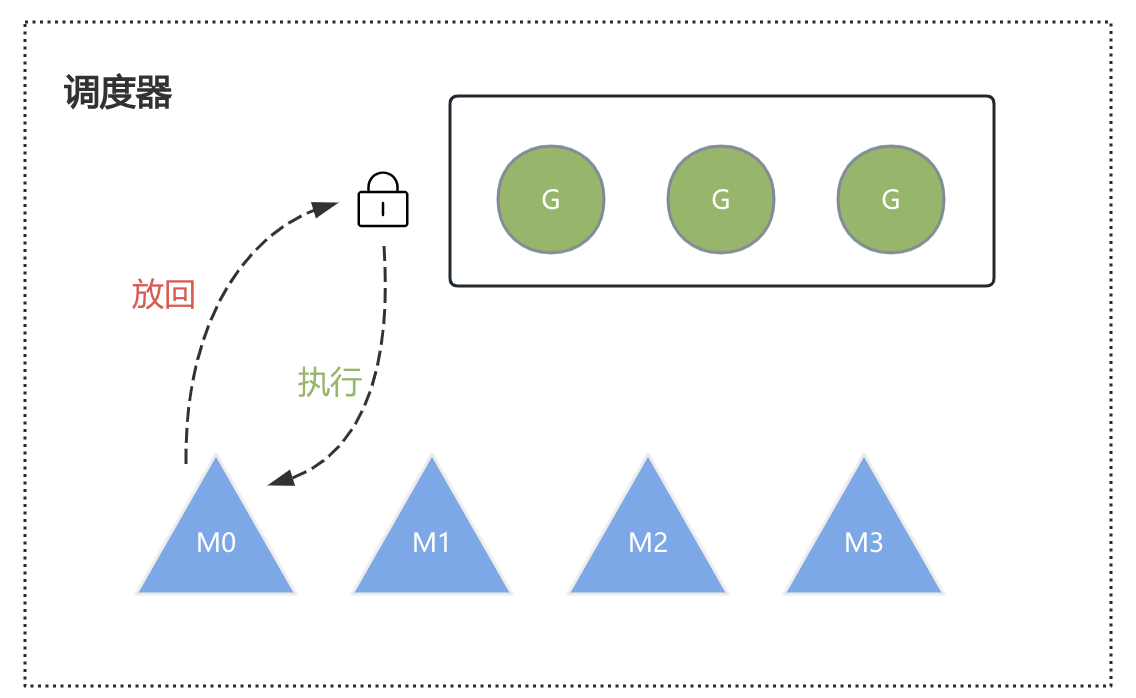
Go早期的调度模型是GM的,M想要执行、放回G都必须访问全局G队列,并且M有多个,即多线程访问同一资源需要加锁进行保证互斥/同步,所以全局G队列是有互斥锁进行保护的。
老调度器有几个缺点:
- 创建、销毁、调度G都需要每个M获取锁,这就形成了激烈的锁竞争。
- M转移G会造成延迟和额外的系统负载。比如当G中包含创建新协程的时候,M创建了G’,为了继续执行G,需要把G’交给M’执行,也造成了很差的局部性,因为G’和G是相关的,最好放在M上执行,而不是其他M’。
- 系统调用(CPU在M之间的切换)导致频繁的线程阻塞和取消阻塞操作增加了系统开销。
改进后的调度模型引入了P,因此就变成了GMP模型。Processor,它包含了运行 goroutine 的资源,如果线程想运行 goroutine,必须先获取 P,P 中还包含了可运行的 G 队列。
模型总览
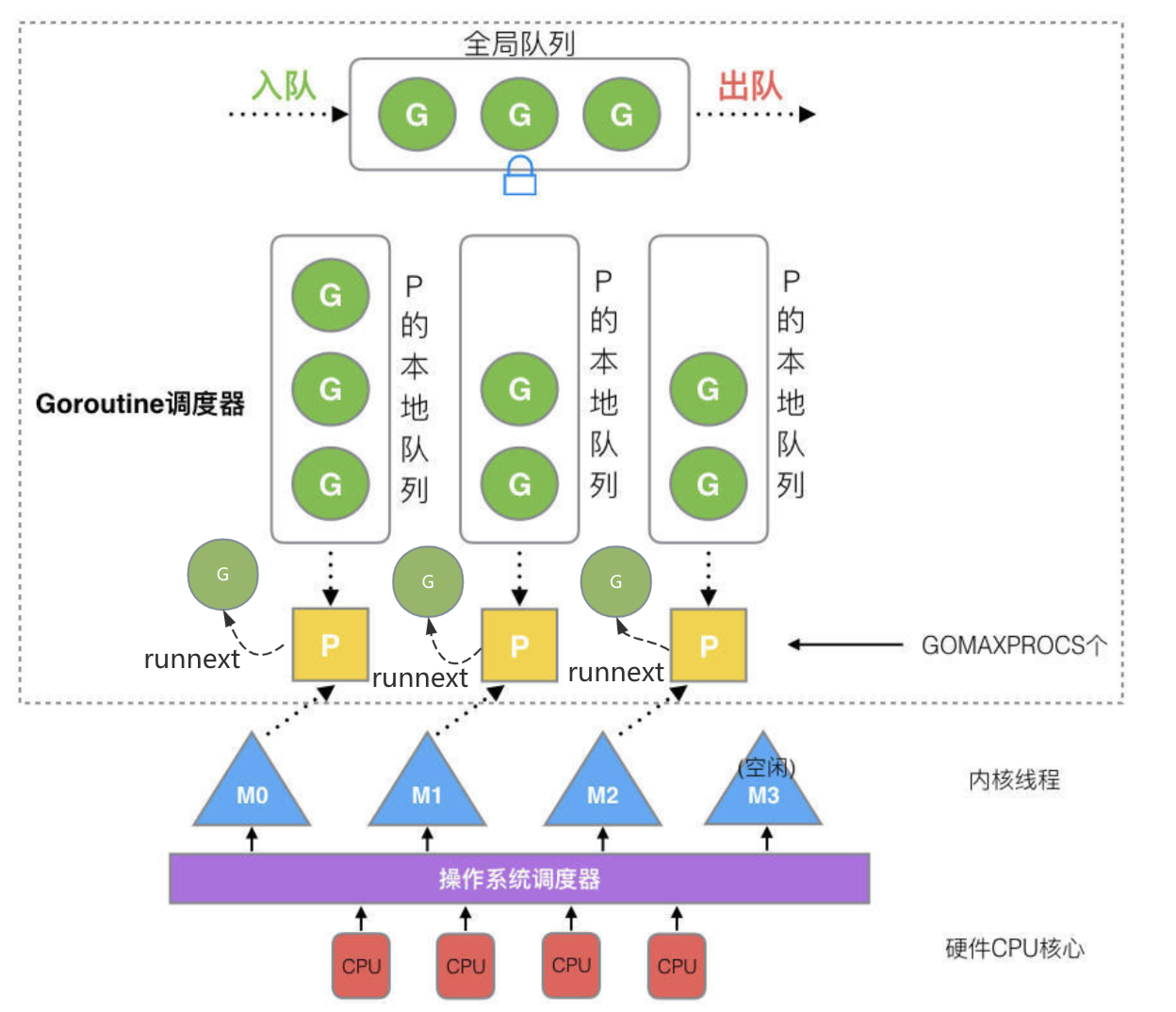
调度策略
1.首先每60次,会先调度一下全局队列中的G以防止饿死,具体globrunqget运行下文会讲
1 | if pp.schedtick%61 == 0 && sched.runqsize > 0 { |
2.从P的本地队列从找可允许的G
1 | if gp, inheritTime := runqget(pp); gp != nil { |
runnext是一个特殊的队列,它只能存放一个G,首先会检查它是否为空,如果不为空,则直接返回该值,否则才会去检查本地队列。然后从链表头部(其实是一个环形数组)拿去一个G然后head++,其中的获取和设置操作都要使用原子,防止并发冲突。
3.如果P的本地队列中没有可运行的G则会去全局队列中查找
1 | if sched.runqsize != 0 { |
因为全局队列是共用的,所以找之前要上锁。首先计算好这次要拿几个G(最多一半,即128个),然后拿走全局队列中的前n个G,放到P的本地队列尾部去。
4.如果全局队列中也没有,则会去检查是否有等待的网络任务,如果有则会拿一个,否则会跳过这一步。
1 | if gcBlackenEnabled != 0 && gcMarkWorkAvailable(pp) && gcController.addIdleMarkWorker() { |
5.如果前面都没拿到则会去其他的P上面偷(steal work)
1 | if mp.spinning || 2*sched.nmspinning.Load() < gomaxprocs-sched.npidle.Load() { |
尝试用别的P的本地队列中偷取一半的G放入自己的本地队列中。
有关P的数量和M的数量问题
- P的数量为
GOMAXPROCS个 - M最大的数量是10000个,但是内核很难支持这么多的线程数。
特殊的M0和G0
M0 是启动程序后的编号为 0 的主线程,这个 M 对应的实例会在全局变量 runtime.m0 中,不需要在 heap 上分配,M0 负责执行初始化操作和启动第一个 G, 在之后 M0 就和其他的 M 一样了。
G0 是每次启动一个 M 都会第一个创建的 goroutine,G0 仅用于负责调度的 G,G0 不指向任何可执行的函数,每个 M 都会有一个自己的 G0。在调度或系统调用时会使用 G0 的栈空间,全局变量的 G0 是 M0 的 G0。