
raft论文阅读
引言
Diego Ongaro在《In search of an understandable consensus algorithm》中提出的一种新的分布式共识算法。正如论文标题所说,Raft算法容易理解。
符号定义
选举超时时间为:electionTimeout
所有的server的总数为:2k+1(其中k为正整数)
状态有三种:leader、follower、candidate
日志条目:log entry
领导选举
- 各
server启动时都是follower状态 - 如果某个
server在经过electionTimeout还没有收到来自leader的信息,那么该server由状态follower转变为candidate,并且首先给自己投上一票,然后向其他server发送请求投票的消息。 server保持candidate的状态直到出现下面三种情况:- 该
server收到了来自大于等于k+1的票数(包括它给自己投的一票),该candidate转为leader - 其他
candidate成为了leader,也就是收到了任期不小于自己的leader发来的消息,该candidate转为follower - 时间达到了
electionTimeout,那么任期+1,该candidate状态不变,并且重新给自己投票,并向其他server发送请求投票信息
- 该
- 每一个
server在一个任期内,只能投票给一个candidate,并且采取的是先来先服务的算法,即哪个candidate的请求投票消息先到达,就给该candidate投票。该限制就确保了一个任期内,至多只有一个server可以成功变为leader。
优化:为了减少
split votes的情况,即该任期内,没有一个candidate成功变为leader,因此给每个candidate设置超时选举时间的时候会给electionTimeout+1个随机时间,论文中给出的数据是(150–300ms)。注:作者还简单描述了另外一个被抛弃的选举想法,即给每一个
candidate一个唯一的优先级,而不是上面的大家都是平等的,candidate如果遇到一个优先级比它更高的,则将票投给它。作者发现这种优先级的思想更不稳定,因此放弃了。
日志复制
一旦有leader被选举出来,则开始服务客户端发来的请求,客户端的请求被执行是分两个阶段的:1.先是记录日志条目,2.然后才是真正的执行命令。
每一个log entry由任期号和索引号来唯一标识。
正常操作情况下,由leader接收客户端的请求,然后记录在自己的日志中,并且将该日志发给所有follower,各follower记录在自己日志中,leader和follower的日志条目应该是保持一致的,但是由于各种网络,server故障的原因所在,会导致日志条目出现不一样的情况,现在需要解决这种不一致的现象,raft中解决不一致的情况是强迫follower同步leader的日志,具体操作如下:
leader会维护一个nextIndex数组用来记录各follower下一次应该记录日志的索引号,该数组初始值为leader最后一条日志条目的索引+1- 当
leader需要向follower发送添加日志条目的请求时,会带上每个follower所对应的nextIndex值的前一个日志条目的任期号prevLogTerm和索引号prevLogIndex用来比较follower的nextIndex的前一个的日志条目是否相等,如果相等说明前面的都是相等的,直接在nextIndex处添加日志即可,如果不相等则nextIndex减1,继续比较前一个是否相等,循环这个过程直到遇到相等的。
优化,上面这种策略是
一次回退一个,下面给出几个优化方法
为了方便说明,使用论文中的图进行辅助解释
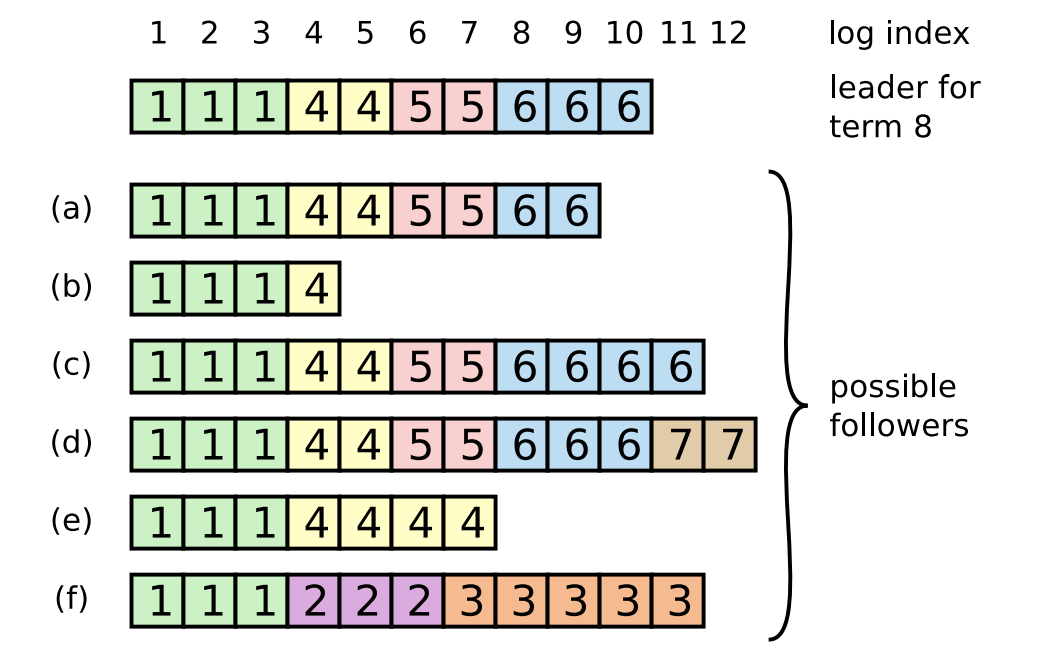
情况1:如果follower中没有prevLogInex,即日志比较少,也就是上面的b这种情况,如果是一个一个回退,则要回退到4,这种情况follower直接返回conflictIndex = len(log)和conflictTerm = None
情况2:如果follower中有prevLogInex,但是任期号和leader中的不相等,上图中的f情况,则返回conflictIndex=第一个出现该term的索引号和conflictTerm=prevLogIndex所对应的任期号
情况3:如果follower中有prevLogInex,并且任期号和leader中的相等,则正常添加就行
上面说的是follower的返回值,leader接收到这些返回值后,做如下的处理:
如果是
conflictTerm = None即情况1,这种时候下次应该就直接比较conflictIndex,则nextIndex=conflictIndex+1(我这里是数组下标从1开始,如果从0开始则不用+1)如果是
leader中有conflictTerm,则将nextIndex设置为leader中该conflictTerm的最后一个,因为并不一定是该任期的所有索引都对不上。举个上面的例子来说a,此时该nextIndex为10。如果是
leader没有conflictTerm,说明该任期整个都对不上,得全部删除,因此nextIndex=conflictIndex,即下次要从follower的前一个任期的最后一条开始比较。
注:作者在论文中提到,在实践情况下,不会出现太多的不一致情况,因此这种优化也不是必要的
安全性
上面领导选举和日志复制所描述的机制并不能确保该共识算法的正确性,即每一个server以同样的顺序执行客户端发来的同样的命令。因此在下面补充了一些限制,以确保算法的正确性。
选举leader的限制
只有拥有了所有已经commited的日志的server才可以成为candidate请求其它server的投票。那怎么保证这个过程呢?
这是通过比较两个server的最后一个日志的任期号和索引号来判断的,只有一个candidate发过来的的请求投票消息中的最后一个日志的任期号大于该server的任期号,或者任期号相同,但是索引号要大于等于该server的索引号,才会把票投给这个candidate,否则直接拒绝投票。
当前leader不能直接提交之前任期的日志
raft论文中的图有点难懂,作者在博士论文中重新画了一下图:
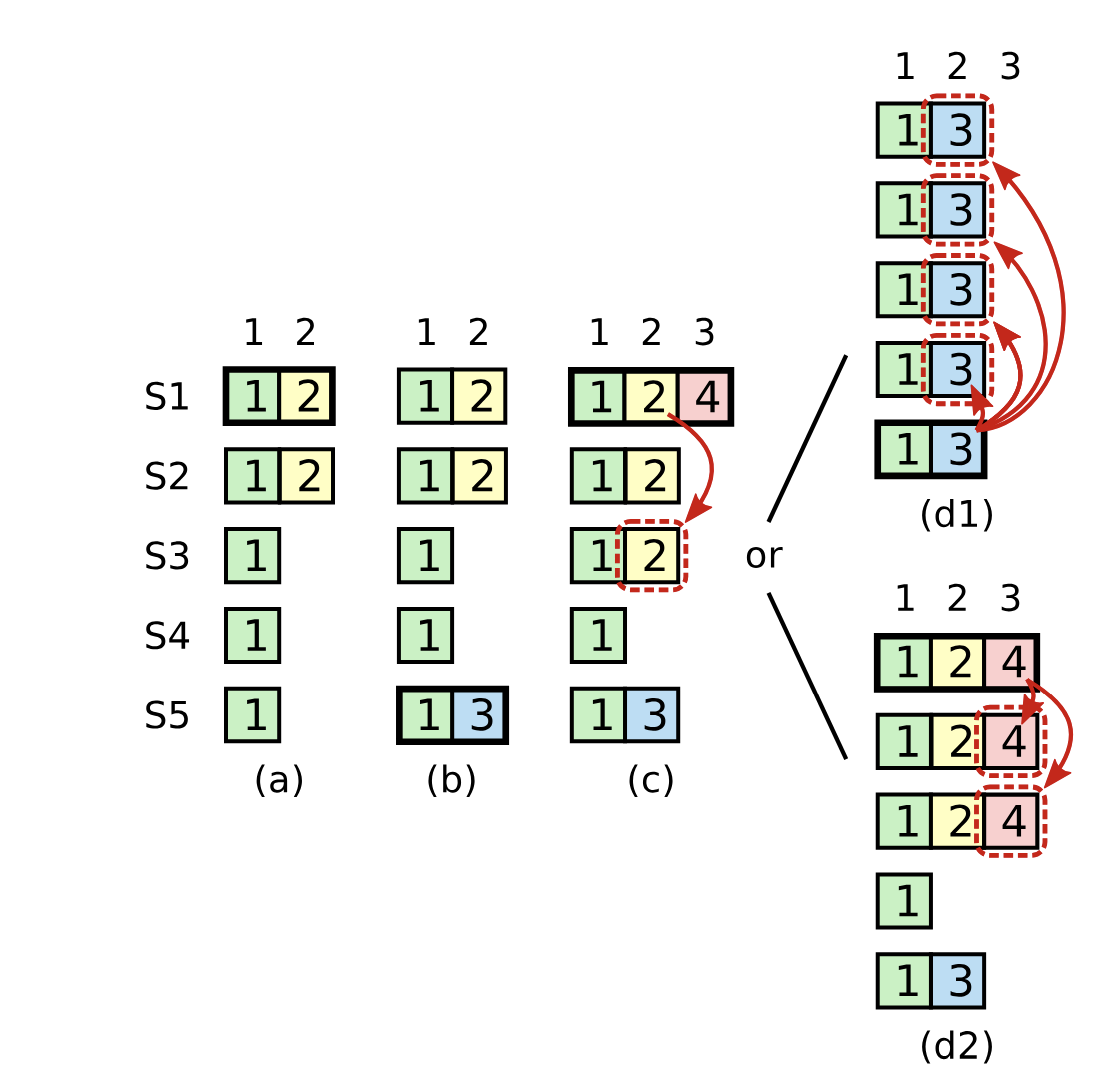
S1在term=4的时候不能直接提交term=2,index=2的这条日志的,如果允许这种情况发生会出现这种奇怪的现象:term=2,index=2被提交后,然后S1崩溃了,这个时候S5可以重新选举为leader因此它的日志条目的任期更新,就会导致它也可能提交term=3,index=2的情况,这个时候就出现了index=2时候提交了两个任期不一样的日志。
在加上限制后,就不会出现上面的这种情况,只会发生d1或者d2的合法情况。