
Redis字典源码学习
特别提醒,本文所涉及的代码是redis3.0,由《Redis设计与实现》作者所注释的版本:地址
与字典相关的文件在
dict.h和dict.c两个文件中
数据结构
1 | typedef struct dictEntry { |
dictEntry是字典中的单个节点,即一个k-v对,注意到这里的值是一个union联合体,键值对中的值可以是一个指向实际值的指针即val,或者是一个无符号的 64 位整数u64或有符号的 64 位整数s64。
1 | typedef struct dictht { |
dictht是一个哈希表,其中存放了很多个链表节点,每个链表是一个dictEntry
1 | typedef struct dict { |
dict是redis中真正提供给外面使用的字典,其中有多个字段,这里只关注核心的两个字段dictht ht[2]和int rehashidx。这里要创建两个哈希表是为了方便rehash,rehashidx主要用于渐进式哈希。
可能第一眼看上面有三个相关的数据结构,有点不太好理解,下面画一个图来描述三者的关系:
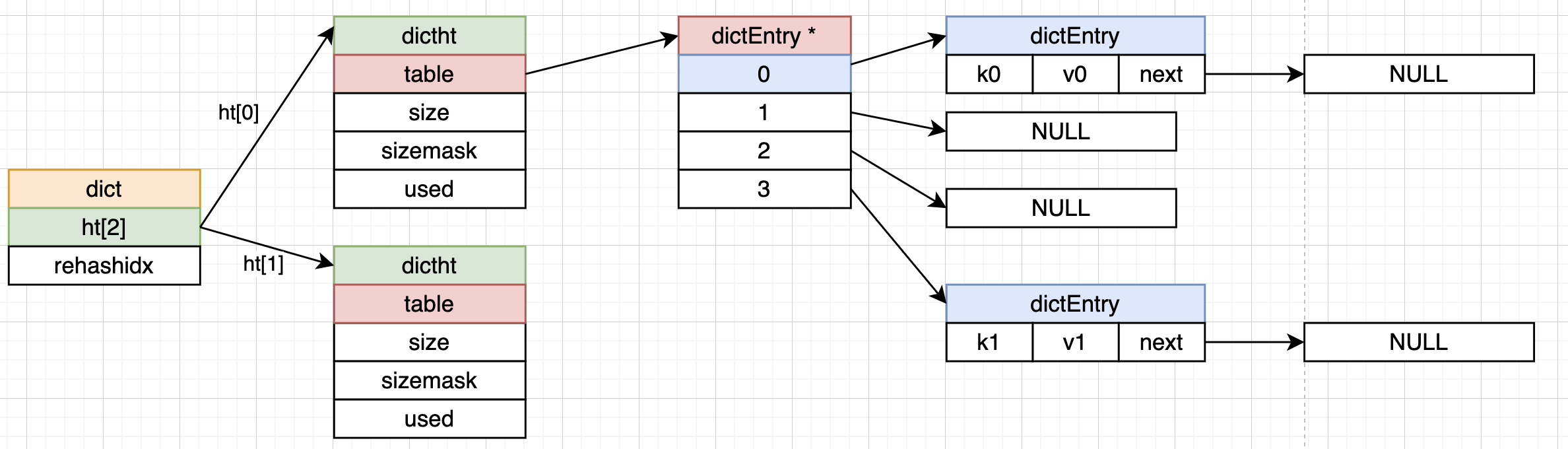
下面介绍学习一下dict的一些增删改查的源码
查找
在字典dict中查找key在哪个链表中,如果存在该key则返回-1,不存在则返回哈希值,即应该在哪个链表中1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27static int _dictKeyIndex(dict *d, const void *key)
{
unsigned int h, idx, table;
dictEntry *he;
if (_dictExpandIfNeeded(d) == DICT_ERR)
return -1;
// 计算 key 的哈希值
h = dictHashKey(d, key);
// T = O(1)
for (table = 0; table <= 1; table++) {
// 计算索引值
idx = h & d->ht[table].sizemask;
// 查找 key 是否存在
// T = O(1)
he = d->ht[table].table[idx];
while(he) {
if (dictCompareKeys(d, key, he->key))
return -1;
he = he->next;
}
// 如果运行到这里时,说明 0 号哈希表中所有节点都不包含 key
// 如果这时 rehahs 正在进行,那么继续对 1 号哈希表进行 rehash
if (!dictIsRehashing(d)) break;
}
// 返回索引值
return idx;
}
- 首先调用函数
_dictExpandIfNeeded(d)判断当前字典是否需要进行扩容 - 先遍历
ht[0]中的链表,然后计算key的哈希值,如果该链表中查询到则直接返回 - 如果在
ht[0]的链表中没找到,则要先判断该字典是否处在rehash中,如果不在,则直接返回前面计算到的idx,否则还要去ht[1]对应的链表中查找
1 | static int _dictExpandIfNeeded(dict *d) |
- 如果字典还未初始化,则进行初始化操作,初始化链表数组大小为4
- 满足两个条件之一,则需要进行扩容操作:字典已使用节点数和字典大小之间的比率接近
1:1并且dict_can_resize为真,或者已使用节点数和字典大小之间的比率超过dict_force_resize_ratio,该值为5。 - 扩容时有个小细节,就是它调用
dictExpand(d, d->ht[0].used*2),传入的大小为已经存在的k-v对的两倍
1 | int dictExpand(dict *d, unsigned long size) |
- 首先会根据传入的
size大小,找到第一个大于等于size的2的幂次方 - 如果
ht[0]为空,则说明这是一次初始化操作 - 如果非空,则说明这是一次
rehash操作,需要打开rehash标识,让字典在进行增删改查的时候进行渐进式哈希。
添加
往一个字典dict中添加一个k-v对,如果key已经存在字典当中,则添加失败,否则插入该k-v对
1 | int dictAdd(dict *d, void *key, void *val) |
- 首先调用
dictAddRaw函数,判断字典d中是否存在key - 如果已经存在则直接返回错误
- 不存在,则插入,并且返回成功
1 | dictEntry *dictAddRaw(dict *d, void *key) |
- 首先判断字典是否处在
rehash中,如果是,则顺带执行单步rehash - 首先使用
_dictKeyIndex(d, key)获取到插入到哪个链表的索引 - 如果当前正在
rehash则应该插入到ht[1]表中,否则是ht[0]表中 - 插入到链表的头部(时间复杂度是O(1))
修改
如果键不存在,则将给定的键值对添加到字典中,如果键已经存在,那么删除旧有的键值对
1 | int dictReplace(dict *d, void *key, void *val) |
- 首先调用
dictAdd(d, key, val)判断是否成功,如果成功说明是添加操作,否则要进行修改操作 - 调用
dictFind(d, key)找到该key对应的节点,修改其中的值
删除
查找并删除包含给定键的节点,成功删除返回DICT_OK,没找到则返回DICT_ERR
1 | static int dictGenericDelete(dict *d, const void *key, int nofree) |
- 如果当前正在
rehash,则协同进行单步的rehash操作 - 首先遍历
ht[0],如果在该链表中没找到,则取遍历ht[1]找到则直接删除