特别提醒,本文所涉及的源码是go1.21.0 darwin/amd64
文件位置:runtime/map.go
哈希表作为一种非常常见的数据结构,在其它语言中也都会有出现,因此本文不对哈希表的概念、用法做解释,专注于go语言中的源码学习。
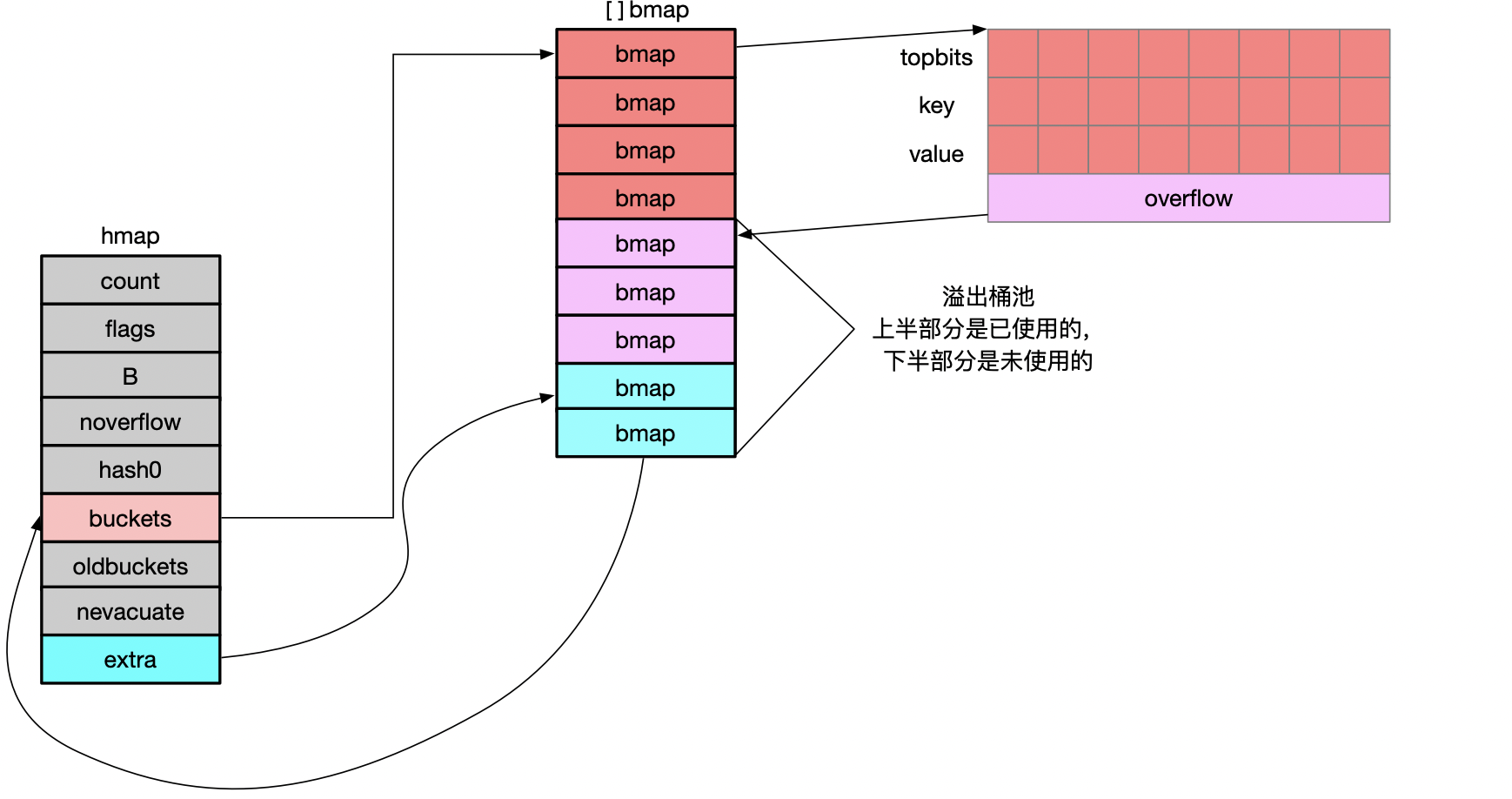
1 数据结构 1 2 3 4 5 6 7 8 9 10 11 type hmap struct { count int flags uint8 B uint8 noverflow uint16 hash0 uint32 buckets unsafe.Pointer oldbuckets unsafe.Pointer nevacuate uintptr extra *mapextra }
1 2 3 4 5 type mapextra struct { overflow *[]*bmap oldoverflow *[]*bmap nextOverflow *bmap }
当map中的kev和value不包含指针时,overflow和oldoverflow才被使用
overflow:hmap.buckets 使用的溢出桶
oldoverflow:hmap.oldbuckets使用的溢出桶
nextOverflow:下一个可以用的溢出桶
1 2 3 4 type bmap struct { tophash [bucketCnt]uint8 }
tophash: $\leq5$时存放的是状态。$\gt5$时存放的是高8位的hash值,用于快速判断key是否存在
emptyRest = 0: 此单元为空,且更高索引的单元也为空
emptyOne = 1: 此单元为空
evacuatedX = 2: 用于表示扩容迁移到新桶前半段区间,即索引没变
evacuatedY = 3: 用于表示扩容迁移到新桶后半段区间,即在新桶中的索引=旧桶索引+扩容前容量大小
evacuatedEmpty = 4: 用于表示此桶已迁移完成
minTopHash = 5: 最小的空桶标记值,小于其则是空桶标志
在runtime/map.go文件中bmap只包含了一个简单的tophash字段,但是在运行期间会根据key和value的类型对bmap的结构进行重建如下:
1 2 3 4 5 6 type bmap struct { topbits [8 ]uint8 keys [8 ]keytype elems [8 ]elemype overflow uintptr }
相关代码在:cmd/compile/internal/reflectdata/reflect.go: MapBucketType
2 构造方法 创建map时,实际上会调用makemap()方法,该方法分析如下:
1 func makemap (t *maptype, hint int , h *hmap)
1 2 3 4 mem, overflow := math.MulUintptr(uintptr (hint), t.Bucket.Size_) if overflow || mem > maxAlloc { hint = 0 }
hint是为map拟分配的容量,再分配前会对拟分配的内存大小进行判断,如果超过限制大小,则会将hint设置为零
1 2 3 4 if h == nil { h = new (hmap) } h.hash0 = fastrand()
初始化h,并设置哈希种子
1 2 3 4 5 B := uint8 (0 ) for overLoadFactor(hint, B) { B++ } h.B = B
首先初始化B为0,然后根据$\frac{hint}{6}>2^B$如果成立则B+1,最后直到B不成立为止,即让$\frac{hint}{2^B}$负载因子小于等于6
map 预分配容量、桶数组长度指数、桶数组长度之间的关系如下表:
kv对数量
指数B
长度$2^B$
0~8
0
1
9~12
1
2
13~24
2
4
25~48
3
8
$2^{B-1}\times6+1$~$ 2^B \times 6$
B
$2^B$
1 2 3 4 5 6 7 8 if h.B != 0 { var nextOverflow *bmap h.buckets, nextOverflow = makeBucketArray(t, h.B, nil ) if nextOverflow != nil { h.extra = new (mapextra) h.extra.nextOverflow = nextOverflow } }
调用makeBucketArray初始化桶数组buckets,如果map容量过大,会提前申请溢出桶
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 func makeBucketArray (t *maptype, b uint8 , dirtyalloc unsafe.Pointer) base := bucketShift(b) nbuckets := base if b >= 4 { nbuckets += bucketShift(b - 4 ) sz := t.Bucket.Size_ * nbuckets up := roundupsize(sz) if up != sz { nbuckets = up / t.Bucket.Size_ } } if dirtyalloc == nil { buckets = newarray(t.Bucket, int (nbuckets)) } else { buckets = dirtyalloc size := t.Bucket.Size_ * nbuckets if t.Bucket.PtrBytes != 0 { memclrHasPointers(buckets, size) } else { memclrNoHeapPointers(buckets, size) } } if base != nbuckets { nextOverflow = (*bmap)(add(buckets, base*uintptr (t.BucketSize))) last := (*bmap)(add(buckets, (nbuckets-1 )*uintptr (t.BucketSize))) last.setoverflow(t, (*bmap)(buckets)) } return buckets, nextOverflow }
如果B大于4的话,会额外多创建$2^{B-4}$个溢出桶(内存对齐),并将h.nextOverflow指向第一个溢出桶的地址,最后一个溢出桶的地址设置为h.buckets(方便判断溢出桶已经用完)
3 读操作 map的读操作一般是通过下标或者遍历进行的:
1 2 3 4 5 value = hash[key] for k,v := range hash {}
这两种方式都能够读取,但是所使用到的函数和底层的原理是不同的
3.1 通过key来读取 1 2 value := hash[key] value,ok := hash[key]
当只需要一个返回值时,会调用mapaccess1()函数
当需要两个返回值时,会调用mapaccess2()函数
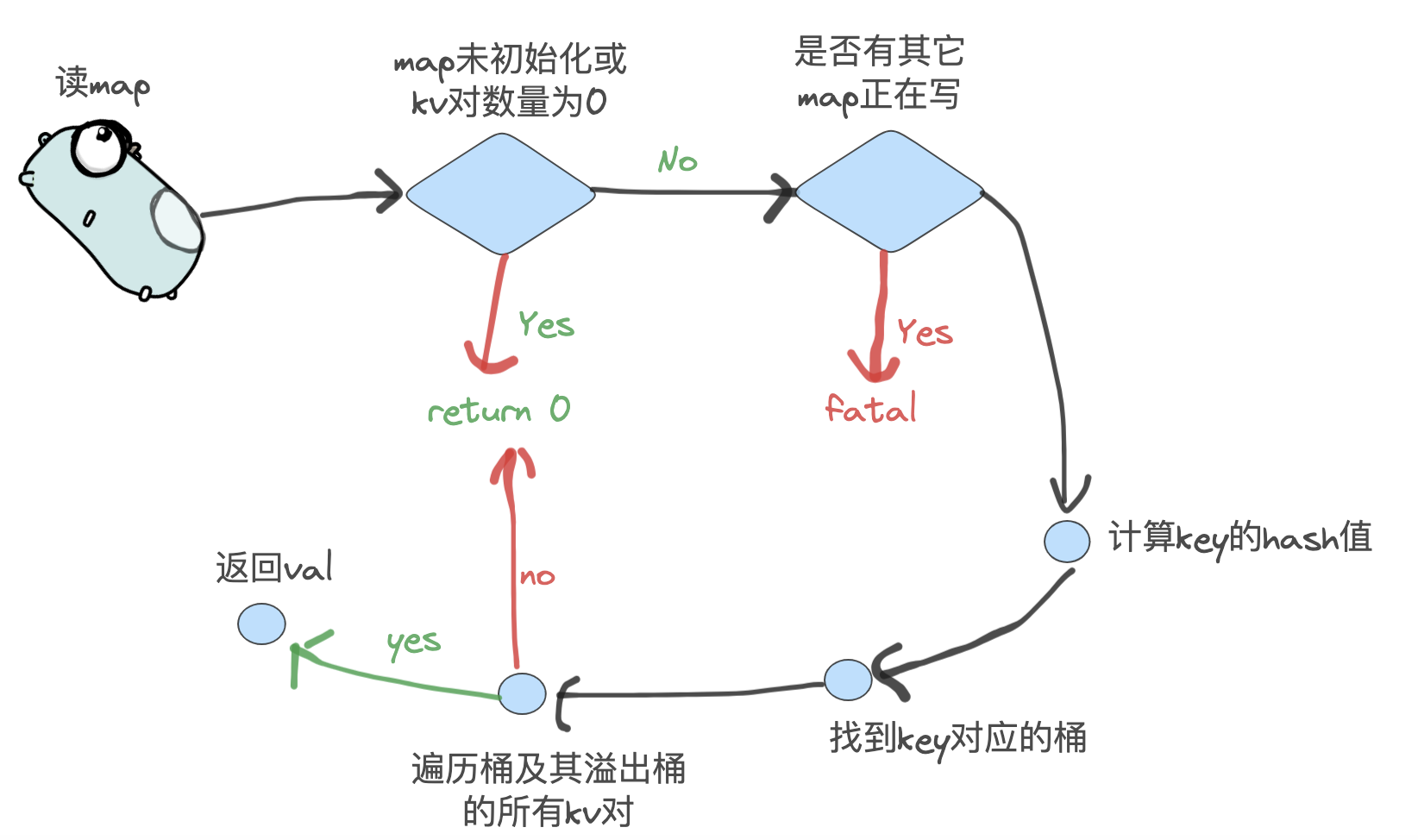
1 2 3 4 5 6 if h == nil || h.count == 0 { if t.HashMightPanic() { t.Hasher(key, 0 ) } return unsafe.Pointer(&zeroVal[0 ]) }
1 如果h未初始化或者map中的k-v对为0,则会直接返回一个零值对象
1 2 3 if h.flags&hashWriting != 0 { fatal("concurrent map read and map write" ) }
2 如果此时有其它的g在对map进行写操作,则直接返回fatal
1 2 3 hash := t.Hasher(key, uintptr (h.hash0)) m := bucketMask(h.B) b := (*bmap)(add(h.buckets, (hash&m)*uintptr (t.BucketSize)))
3 通过MapType.Hasher()方法得到key对应的hash值并对桶数量取模,获取对应桶的索引
1 2 3 4 5 6 7 8 9 10 if c := h.oldbuckets; c != nil { if !h.sameSizeGrow() { m >>= 1 } oldb := (*bmap)(add(c, (hash&m)*uintptr (t.BucketSize))) if !evacuated(oldb) { b = oldb } }
4 判断map是否正在扩容,首先判断是否进行增量扩容,倘若是的话,需要将m除以2,因为旧桶的长度只是新桶的一半,然后通过evacuated判断要找的桶是否在旧的桶数组里面,如果是则需要去旧的桶数组当中去找。
1 2 3 4 5 6 7 8 9 top := tophash(hash) func tophash (hash uintptr ) uint8 { top := uint8 (hash >> (goarch.PtrSize*8 - 8 )) if top < minTopHash { top += minTopHash } return top }
5 获取hash值的高八位,如果该值小于5,会加上5,以避开0~4这个区间
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 bucketloop: for ; b != nil ; b = b.overflow(t) { for i := uintptr (0 ); i < bucketCnt; i++ { if b.tophash[i] != top { if b.tophash[i] == emptyRest { break bucketloop } continue } k := add(unsafe.Pointer(b), dataOffset+i*uintptr (t.KeySize)) if t.IndirectKey() { k = *((*unsafe.Pointer)(k)) } if t.Key.Equal(key, k) { e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr (t.KeySize)+i*uintptr (t.ValueSize)) if t.IndirectElem() { e = *((*unsafe.Pointer)(e)) } return e } } } return unsafe.Pointer(&zeroVal[0 ])
6 外层for循环会遍历要查找的那个桶及其后续的溢出桶,里层for循环遍历桶内的key-value对。遍历时首先查询高8位的tophash值,如果和key的对应不上,并且当前位置的tophash为0,则后面没有元素,直接结束这个桶的遍历。倘若找到了相等的key,则通过地址偏移的方式取到 value 并返回,如果遍历了所有桶都没找到,则返回一个零值。
4 写操作 写操作的实现由mapassign函数实现
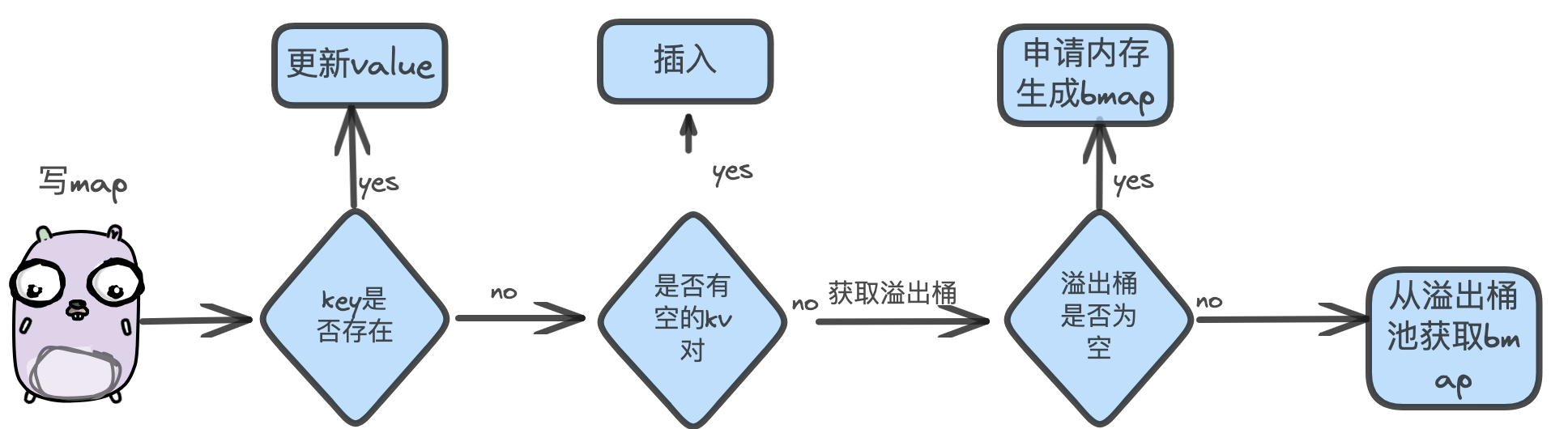
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 func mapassign (t *maptype, h *hmap, key unsafe.Pointer) hash := t.hasher(key, uintptr (h.hash0)) if h.buckets == nil { h.buckets = newobject(t.bucket) } again: bucket := hash & bucketMask(h.B) if h.growing() { growWork(t, h, bucket) } b := (*bmap)(add(h.buckets, bucket*uintptr (t.bucketsize))) top := tophash(hash) var inserti *uint8 var insertk unsafe.Pointer var elem unsafe.Pointer bucketloop: for { for i := uintptr (0 ); i < bucketCnt; i++ { if b.tophash[i] != top { if isEmpty(b.tophash[i]) && inserti == nil { inserti = &b.tophash[i] insertk = add(unsafe.Pointer(b), dataOffset+i*uintptr (t.keysize)) elem = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr (t.keysize)+i*uintptr (t.elemsize)) } if b.tophash[i] == emptyRest { break bucketloop } continue } k := add(unsafe.Pointer(b), dataOffset+i*uintptr (t.keysize)) if !t.key.equal(key, k) { continue } elem = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr (t.keysize)+i*uintptr (t.elemsize)) goto done } ovf := b.overflow(t) if ovf == nil { break } b = ovf } if !h.growing() && (overLoadFactor(h.count+1 , h.B) || tooManyOverflowBuckets(h.noverflow, h.B)) { hashGrow(t, h) goto again } if inserti == nil { newb := h.newoverflow(t, b) inserti = &newb.tophash[0 ] insertk = add(unsafe.Pointer(newb), dataOffset) elem = add(insertk, bucketCnt*uintptr (t.keysize)) } *inserti = top h.count++ done: return elem }
5 删除操作 map相关的删除操作在mapdelete()函数下面,与更新操作类似,多了一个修改当前tophash状态的步骤
首先会将当前的tophash[i]更新为emptyOne,这个不仅仅是操作自己的tophash[i]还要判断它的下一个是不是emptyRest,如果下一个为emptyRest,那么就可以将tophash[i]进一步更新为emptyRest,并且还需要判断之前的tophash如果之前的为emptyOne则要修改为emptyRest
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 func mapdelete (t *maptype, h *hmap, key unsafe.Pointer) if h == nil || h.count == 0 { if t.HashMightPanic() { t.Hasher(key, 0 ) } return } if h.flags&hashWriting != 0 { fatal("concurrent map writes" ) } hash := t.Hasher(key, uintptr (h.hash0)) h.flags ^= hashWriting bucket := hash & bucketMask(h.B) if h.growing() { growWork(t, h, bucket) } b := (*bmap)(add(h.buckets, bucket*uintptr (t.BucketSize))) bOrig := b top := tophash(hash) search: for ; b != nil ; b = b.overflow(t) { for i := uintptr (0 ); i < bucketCnt; i++ { if b.tophash[i] != top { if b.tophash[i] == emptyRest { break search } continue } k := add(unsafe.Pointer(b), dataOffset+i*uintptr (t.KeySize)) k2 := k if t.IndirectKey() { k2 = *((*unsafe.Pointer)(k2)) } if !t.Key.Equal(key, k2) { continue } if t.IndirectKey() { *(*unsafe.Pointer)(k) = nil } else if t.Key.PtrBytes != 0 { memclrHasPointers(k, t.Key.Size_) } e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr (t.KeySize)+i*uintptr (t.ValueSize)) if t.IndirectElem() { *(*unsafe.Pointer)(e) = nil } else if t.Elem.PtrBytes != 0 { memclrHasPointers(e, t.Elem.Size_) } else { memclrNoHeapPointers(e, t.Elem.Size_) } b.tophash[i] = emptyOne if i == bucketCnt-1 { if b.overflow(t) != nil && b.overflow(t).tophash[0 ] != emptyRest { goto notLast } } else { if b.tophash[i+1 ] != emptyRest { goto notLast } } for { b.tophash[i] = emptyRest if i == 0 { if b == bOrig { break } c := b for b = bOrig; b.overflow(t) != c; b = b.overflow(t) { } i = bucketCnt - 1 } else { i-- } if b.tophash[i] != emptyOne { break } } notLast: h.count-- if h.count == 0 { h.hash0 = fastrand() } break search } } if h.flags&hashWriting == 0 { fatal("concurrent map writes" ) } h.flags &^= hashWriting }
6 扩容操作
等量扩容:负载因子没超过6,但是溢出桶的数量大于等于$1<<min(B,15)$,新桶数组的长度跟旧的一样,相当于是将k-v对重新hash
增量扩容:负载因子超过6,新桶数组的长度是旧的两倍
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 func hashGrow (t *maptype, h *hmap) bigger := uint8 (1 ) if !overLoadFactor(h.count+1 , h.B) { bigger = 0 h.flags |= sameSizeGrow } oldbuckets := h.buckets newbuckets, nextOverflow := makeBucketArray(t, h.B+bigger, nil ) flags := h.flags &^ (iterator | oldIterator) if h.flags&iterator != 0 { flags |= oldIterator } h.B += bigger h.flags = flags h.oldbuckets = oldbuckets h.buckets = newbuckets h.nevacuate = 0 h.noverflow = 0 if h.extra != nil && h.extra.overflow != nil { if h.extra.oldoverflow != nil { throw("oldoverflow is not nil" ) } h.extra.oldoverflow = h.extra.overflow h.extra.overflow = nil } if nextOverflow != nil { if h.extra == nil { h.extra = new (mapextra) } h.extra.nextOverflow = nextOverflow } }
该函数的逻辑还是比较简单,并且hashGrow只在mapassign中出现,就是说只有在新值插入的时候才可能触发扩容。
下面来分析growWork()函数:
1 2 3 4 5 6 7 8 9 func growWork (t *maptype, h *hmap, bucket uintptr ) evacuate(t, h, bucket&h.oldbucketmask()) if h.growing() { evacuate(t, h, h.nevacuate) } }
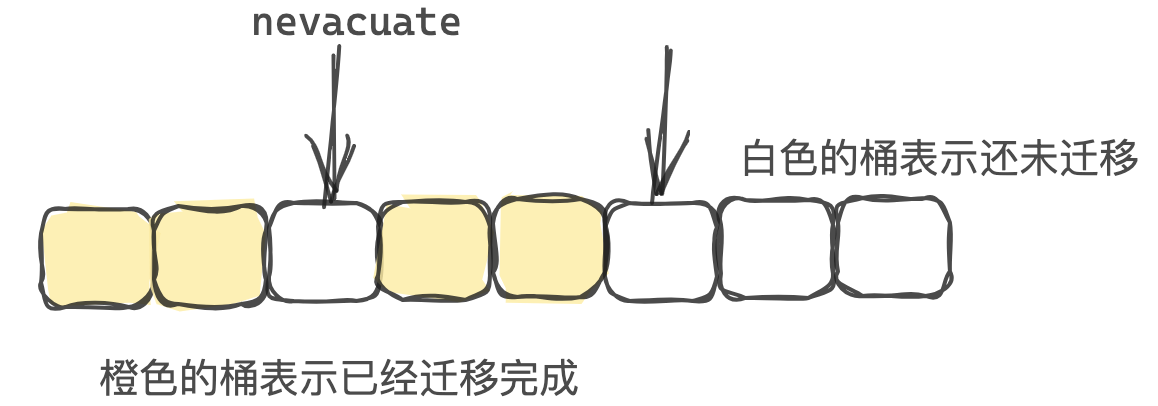
因为使用的是渐进式扩容,因此在插入和删除操作中,如果此时map正在扩容,则每一个操作都会利用growWork()函数迁移最多两个桶,一个是当时操作的桶,还有一个就是nevacuate指向的桶,另外要注意的是这里的一个桶是包括它所指向的溢出桶的。具体的迁移逻辑在evacuate()函数中
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 type evacDst struct { b *bmap i int k unsafe.Pointer e unsafe.Pointer } func evacuate (t *maptype, h *hmap, oldbucket uintptr ) b := (*bmap)(add(h.oldbuckets, oldbucket*uintptr (t.BucketSize))) newbit := h.noldbuckets() if !evacuated(b) { var xy [2 ]evacDst x := &xy[0 ] x.b = (*bmap)(add(h.buckets, oldbucket*uintptr (t.BucketSize))) x.k = add(unsafe.Pointer(x.b), dataOffset) x.e = add(x.k, bucketCnt*uintptr (t.KeySize)) if !h.sameSizeGrow() { y := &xy[1 ] y.b = (*bmap)(add(h.buckets, (oldbucket+newbit)*uintptr (t.BucketSize))) y.k = add(unsafe.Pointer(y.b), dataOffset) y.e = add(y.k, bucketCnt*uintptr (t.KeySize)) } for ; b != nil ; b = b.overflow(t) { k := add(unsafe.Pointer(b), dataOffset) e := add(k, bucketCnt*uintptr (t.KeySize)) for i := 0 ; i < bucketCnt; i, k, e = i+1 , add(k, uintptr (t.KeySize)), add(e, uintptr (t.ValueSize)) { top := b.tophash[i] if isEmpty(top) { b.tophash[i] = evacuatedEmpty continue } if top < minTopHash { throw("bad map state" ) } k2 := k if t.IndirectKey() { k2 = *((*unsafe.Pointer)(k2)) } var useY uint8 if !h.sameSizeGrow() { hash := t.Hasher(k2, uintptr (h.hash0)) if h.flags&iterator != 0 && !t.ReflexiveKey() && !t.Key.Equal(k2, k2) { useY = top & 1 top = tophash(hash) } else { if hash&newbit != 0 { useY = 1 } } } if evacuatedX+1 != evacuatedY || evacuatedX^1 != evacuatedY { throw("bad evacuatedN" ) } b.tophash[i] = evacuatedX + useY dst := &xy[useY] if dst.i == bucketCnt { dst.b = h.newoverflow(t, dst.b) dst.i = 0 dst.k = add(unsafe.Pointer(dst.b), dataOffset) dst.e = add(dst.k, bucketCnt*uintptr (t.KeySize)) } dst.b.tophash[dst.i&(bucketCnt-1 )] = top if t.IndirectKey() { *(*unsafe.Pointer)(dst.k) = k2 } else { typedmemmove(t.Key, dst.k, k) } if t.IndirectElem() { *(*unsafe.Pointer)(dst.e) = *(*unsafe.Pointer)(e) } else { typedmemmove(t.Elem, dst.e, e) } dst.i++ dst.k = add(dst.k, uintptr (t.KeySize)) dst.e = add(dst.e, uintptr (t.ValueSize)) } } if h.flags&oldIterator == 0 && t.Bucket.PtrBytes != 0 { b := add(h.oldbuckets, oldbucket*uintptr (t.BucketSize)) ptr := add(b, dataOffset) n := uintptr (t.BucketSize) - dataOffset memclrHasPointers(ptr, n) } } if oldbucket == h.nevacuate { advanceEvacuationMark(h, t, newbit) } }
解释一下为什么增量扩容,旧桶只会出现在新桶的两个位置
迁移完nevacuate桶后,它会+1,这个时候可能+1的这个桶之前被迁移过了,所以需要继续往后找到一个还未没迁移的桶,该逻辑在advanceEvacuationMark函数中:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 func advanceEvacuationMark (h *hmap, t *maptype, newbit uintptr ) h.nevacuate++ stop := h.nevacuate + 1024 if stop > newbit { stop = newbit } for h.nevacuate != stop && bucketEvacuated(t, h, h.nevacuate) { h.nevacuate++ } if h.nevacuate == newbit { h.oldbuckets = nil if h.extra != nil { h.extra.oldoverflow = nil } h.flags &^= sameSizeGrow } }